
正規表現を簡単にチェックできるサイト
日付 タグ hugo カテゴリ hugo目次
Ruby向けだが正規表現チェックに便利なサイト
正規表現チェッカーのサイトRubularはRuby以外でも有益だ
以前トップページ向けにアイキャッチを抽出する際にHugoのfindRE関数を使って対象となる部分の抽出を行なったが、 ( ==> トップページにアイキャッチのサムネイル画像を入れる )
自分がいつもスクリプト等で正規表現関連の条件判定や抽出文を書くときに参考にしているのがRubularだ。 もともとはRuby向けの正規表現チェックのサイトだが、正規表現自体は多くの言語で利用できるため、Ruby以外の言語を使用している場合でもRubularのサイトを利用すると便利である。
Rubularのサイトの使い方はとても簡単だ。
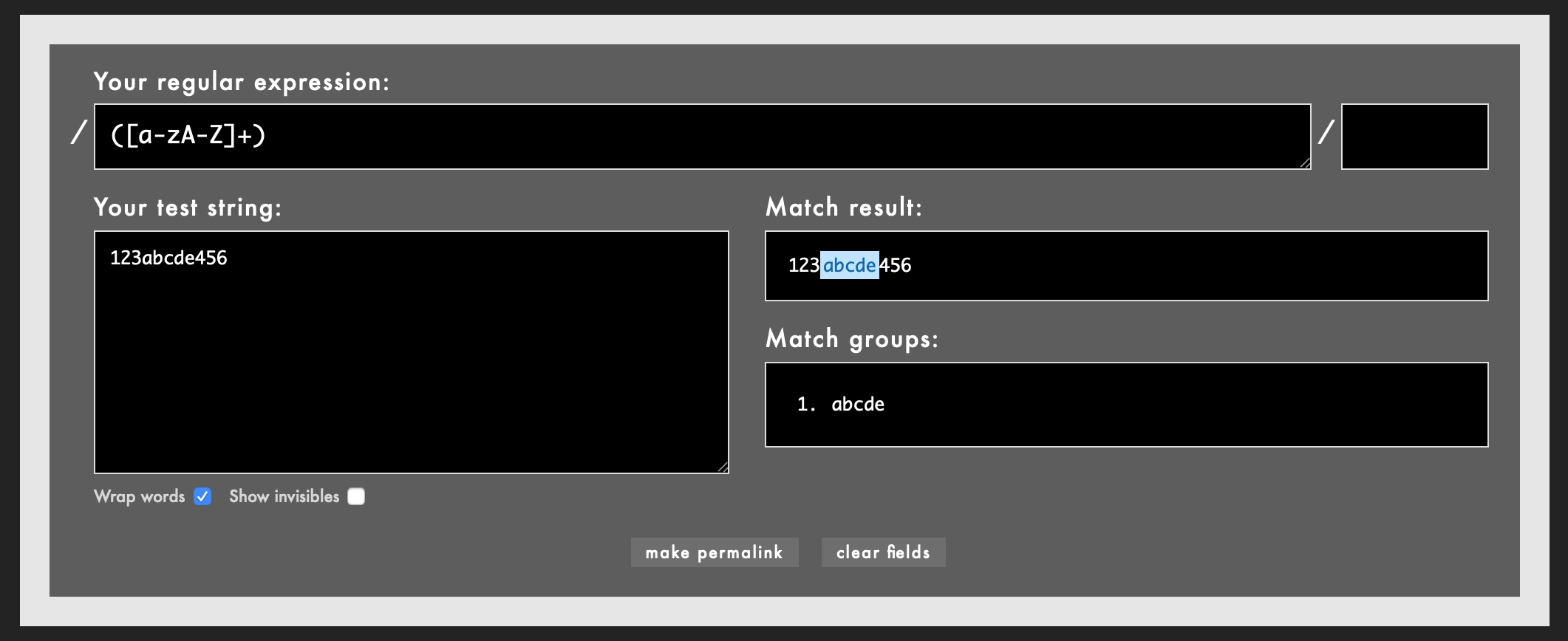
「Your regular expression」に抽出したいパターンを入れて、「Your test string」に対象となる文章を入力する。
例えば、英小文字大文字の部分を抜き出したい場合には、抽出するパターンは
([a-zA-Z]+)
そして、テスト的な対象の文章として、
123abcde456
を入力すると、結果が即時反映され、マッチした結果(マッチしたグループ含む一文)と、マッチしたグループが表示される。
実際、この結果は、irbコマンドでrubyを実行してみれば、
irb(main):002:0> "123abcde456".match(/([a-zA-Z]+)/)
=> #<MatchData "abcde" 1:"abcde">
一方、Hugoの場合
{{ $md := findRE "([a-zA-Z]+)" "123abcde456" }}
=> $md = [abcde]というリスト(1つだけ要素を持つ)での結果となる。
マッチしたグループにはならないHugoのfindRE
なお、 ( ==> トップページにアイキャッチのサムネイル画像を入れる ) でも言及していたが、HugoのfindRE関数はマッチしたグループを返すのではなく、マッチした部分文字列全体を返す。
例:
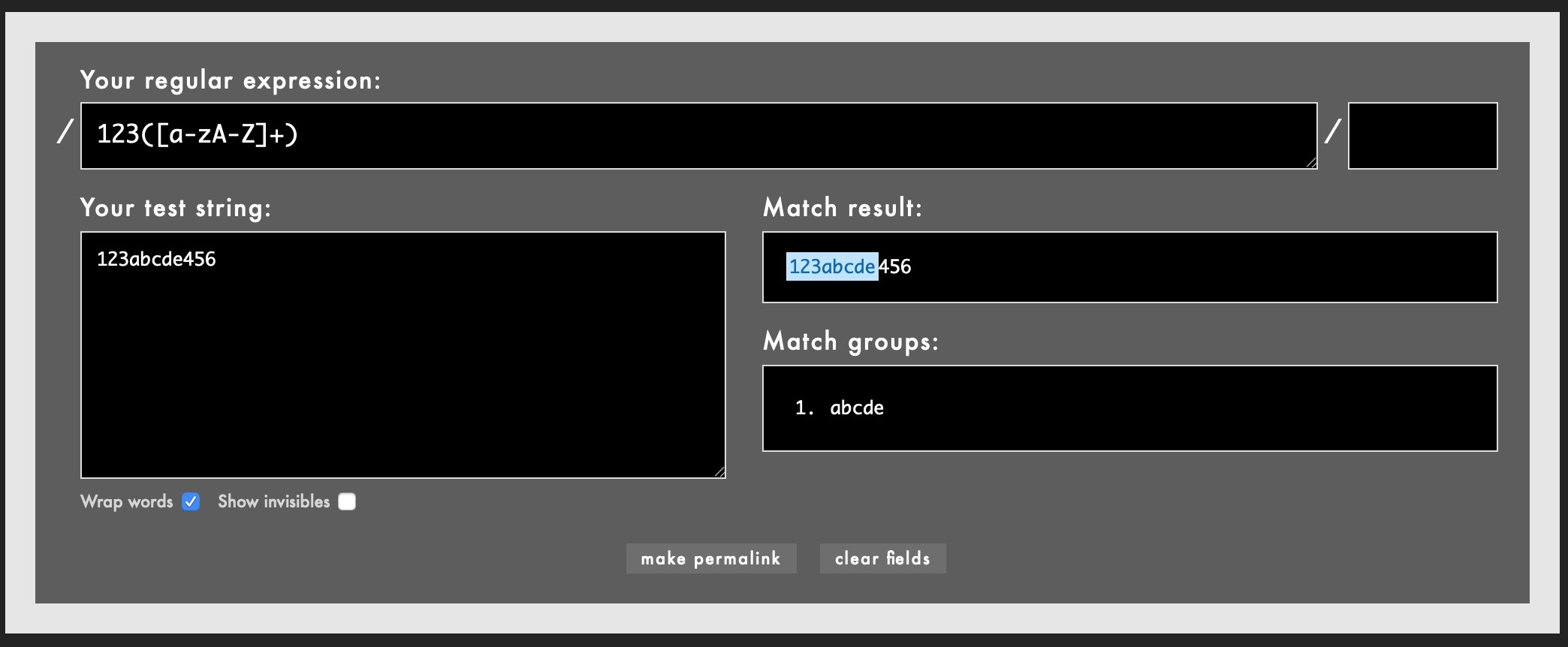
マッチさせたいパターン:
123([a-zA-Z]+)
対象とするテスト文章:
123abcde456
Rubularのサイトでの結果
irbでのRubyの結果
irb(main):001:0> "123abcde456".match(/123([a-zA-Z]+)/)
=> #<MatchData "123abcde" 1:"abcde">
Hugoでの結果
{{ $md := findRE "123([a-zA-Z]+)" "123abcde456" }}
=> $md = [123abcde]というリスト(1つだけ要素を持つ)での結果となる。
Hugoの場合は、このあたりの点に注意しつつ、RubularのサイトのMatch resultで示される結果の方を参考にするといいだろう。